Z-Image-i2L (Image to LoRA)
创建: 2026-01-28更新: 2026-01-28

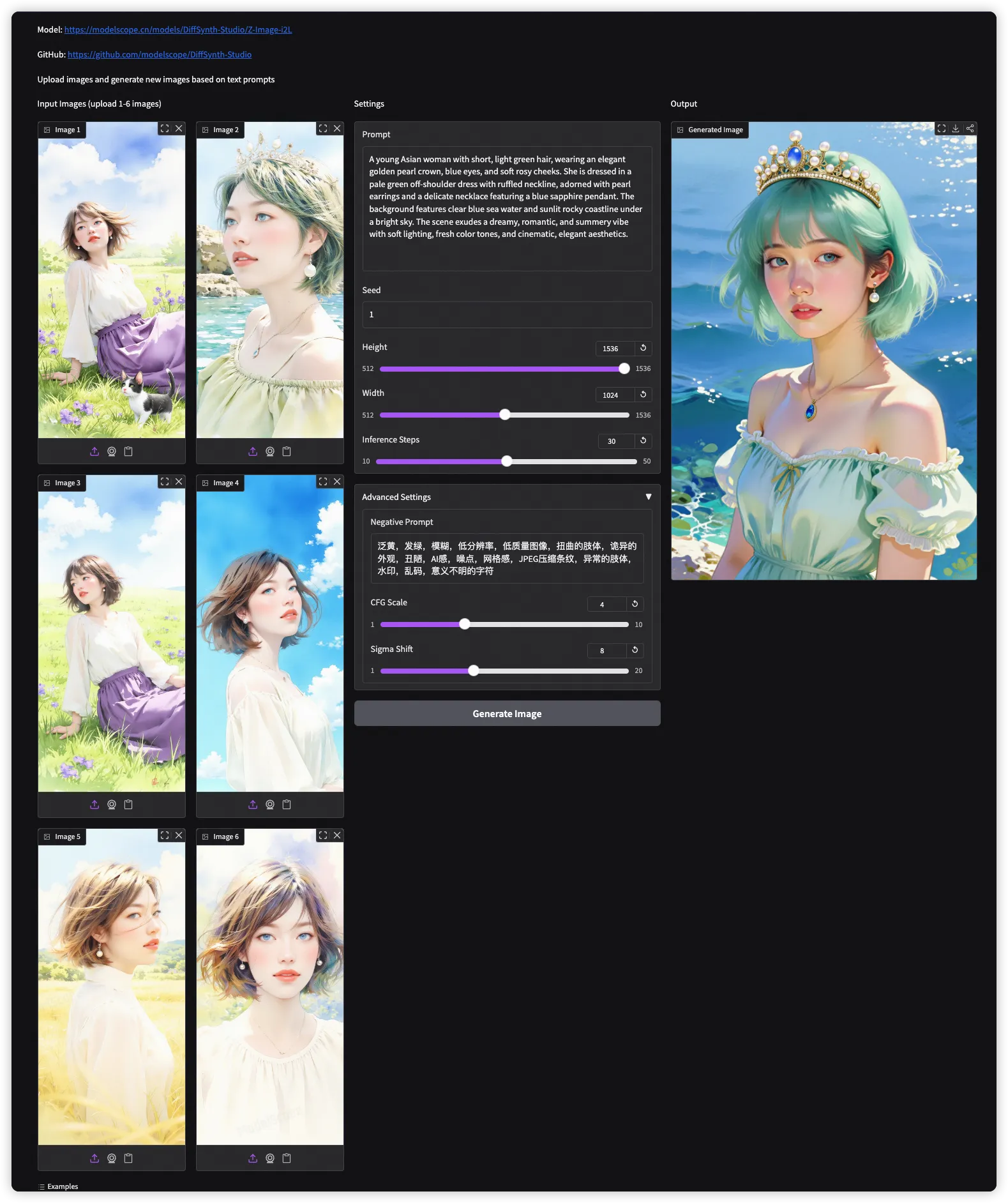
i2L(Image to LoRA)模型是以疯狂的思路设计的模型结构。模型的输入为一张图片,输出为这张图片训练出的 LoRA 模型。本模型基于之前的 Qwen-Image-i2L(模型、技术博客),进一步完善并迁移到 Z-Image,着重增强了模型的风格保持能力。
为保证生成的图像质量,建议按以下参数使用本模型产生的 LoRA 模型:
使用负向提示词
中文:"泛黄,发绿,模糊,低分辨率,低质量图像,扭曲的肢体,诡异的外观,丑陋,AI感,噪点,网格感,JPEG压缩条纹,异常的肢体,水印,乱码,意义不明的字符"
英文:"Yellowed, green-tinted, blurry, low-resolution, low-quality image, distorted limbs, eerie appearance, ugly, AI-looking, noise, grid-like artifacts, JPEG compression artifacts, abnormal limbs, watermark, garbled text, meaningless characters"
cfg_scale = 4 sigma_shift = 8
仅在正向提示词侧启用 LoRA,在负向提示词侧关闭 LoRA,这会提升图像质量
在线体验:https://modelscope.cn/studios/DiffSynth-Studio/Z-Image-i2L
返图区
暂无返图